
At Extend, we are committed to delivering a reliable, scalable, and performant document infrastructure that leading AI teams can trust to ship agents in production. This is not a theoretical commitment. We build our products and benchmarks around real-world use cases and systems of record documents because production document processing is judged by how the system performs on the hardest documents, not the cleanest examples. Long array extraction is one such example of a difficult problem in production.
Extraction is central to document processing because it captures the critical inputs in unstructured documents and transforms them into structured data. Long array extraction is the ability to capture every repeated item in a document, preserving the cardinality of the underlying record set, the attributes associated with each record, and the relationships between those attributes across pages, sections, tables, and document layouts.
For example, a clinical adverse-event listing might contain 1,283 individual events spread over 234 pages. A Wells Fargo combined statement covers two accounts and 1,100 transactions over 60 pages. A motion for summary judgment contains 705 numbered factual paragraphs over 96 pages.
LongArray-Extract measures whether a system can accurately reconstruct large sets of repeated records from benchmark documents modeled on production systems of record and the long-array use cases we see in customer pipelines. Similar to RealDoc-Bench, it is designed around production-style documents and customer-relevant workloads. Both benchmarks are open-sourced to provide transparency and reproducibility.
TLDR
LongArray-Extract tests whether extraction systems can return complete, schema-faithful arrays when the output grows from a dozen of rows to thousands.
Extend MAX completed every document at 99.2% accuracy, 2.8x faster than the closest peer. The long tail exposed tradeoffs in completion rate, latency, and partial-output behavior.
Extend MAX completed every document at 99.2% accuracy, 2.8x faster than the closest peer.
Failures count as 0%
Extend MAX scored every document
Faster than closest peer
Transactions in one PDF
2.8x faster than the closest peer
Accuracy is aggregate mean per-document accuracy across all 45 PDFs. Latency is mean wall-clock time per document.
Extend MAX reached 99.2% aggregate accuracy at 301s mean latency.
The closest peer in accuracy reached 97.4%, but ran in 846s mean latency. That makes Extend MAX 2.8x faster while still leading by 1.7 accuracy points.
Mean per-document accuracy
Each PDF contributes one score. Failed or timed-out runs count as 0%, so completion is reflected in the accuracy.
How we evaluated
Most extraction tests stop at short documents or fixed field sets. This benchmark focuses on the production failure mode we see when the answer is itself large: the model or extraction system has to keep emitting rows, preserve row-level context, avoid duplicates, and return every expected item.
The dataset
LongArray-Extract covers use cases we see in production across customer pipelines. For example, dense financial statements with detailed transaction rows, clinical reports with extensive event rows, and enumerated paragraphs for court documents. Each document has generated ground truth, so missing rows and incorrect fields can be scored directly instead of inferred from spot checks.
What we measured
The primary metric is per-document extraction accuracy. Each system returns structured JSON for the full document. We compare the extracted output to the expected output field by field, then aggregate those matches into a document score.
The benchmark also tracks completion and latency. A response that fails, times out, or returns an unscoreable output is not the same as a low-quality completed extraction. For reporting, we show both quality and completion behavior because production systems need both.
Methodology
We evaluated Extend MAX, raw frontier models, and document-AI platforms on the same benchmark documents. The raw frontier-model baselines were run without custom chunking or retry logic, matching the "send this document to a model and ask for JSON" experience. Extend MAX and competitor platforms were evaluated through their extraction systems and API modes, including LlamaParse Standard and LlamaParse Agentic.
All outputs are normalized into a common scoring format. Bank statement descriptions use fuzzy matching to avoid over-penalizing punctuation or whitespace differences. Legal pleading court names also use fuzzy matching, and vendor-specific response shape differences are normalized before scoring to ensure fairness. Failed runs are tracked separately; when we report mean per-document accuracy, failed documents contribute zero.
What we found
Mean per-document accuracy weights every PDF equally, so a small document and a large document each contribute one score. Failed or timed-out runs count as 0%, which makes the metric reflect whether a system can complete the whole extraction, not just how accurate it is on the rows it returns.
Extend MAX led the aggregate benchmark with 99.2% mean per-document accuracy and 100% completion across all 45 documents.
The closest peer reached 97.4%, followed by Claude Opus 4.7 at 83.1% and Reducto Standard at 80.9%.
Mean per-document accuracy
Each PDF contributes one score. Failed or timed-out runs count as 0%.
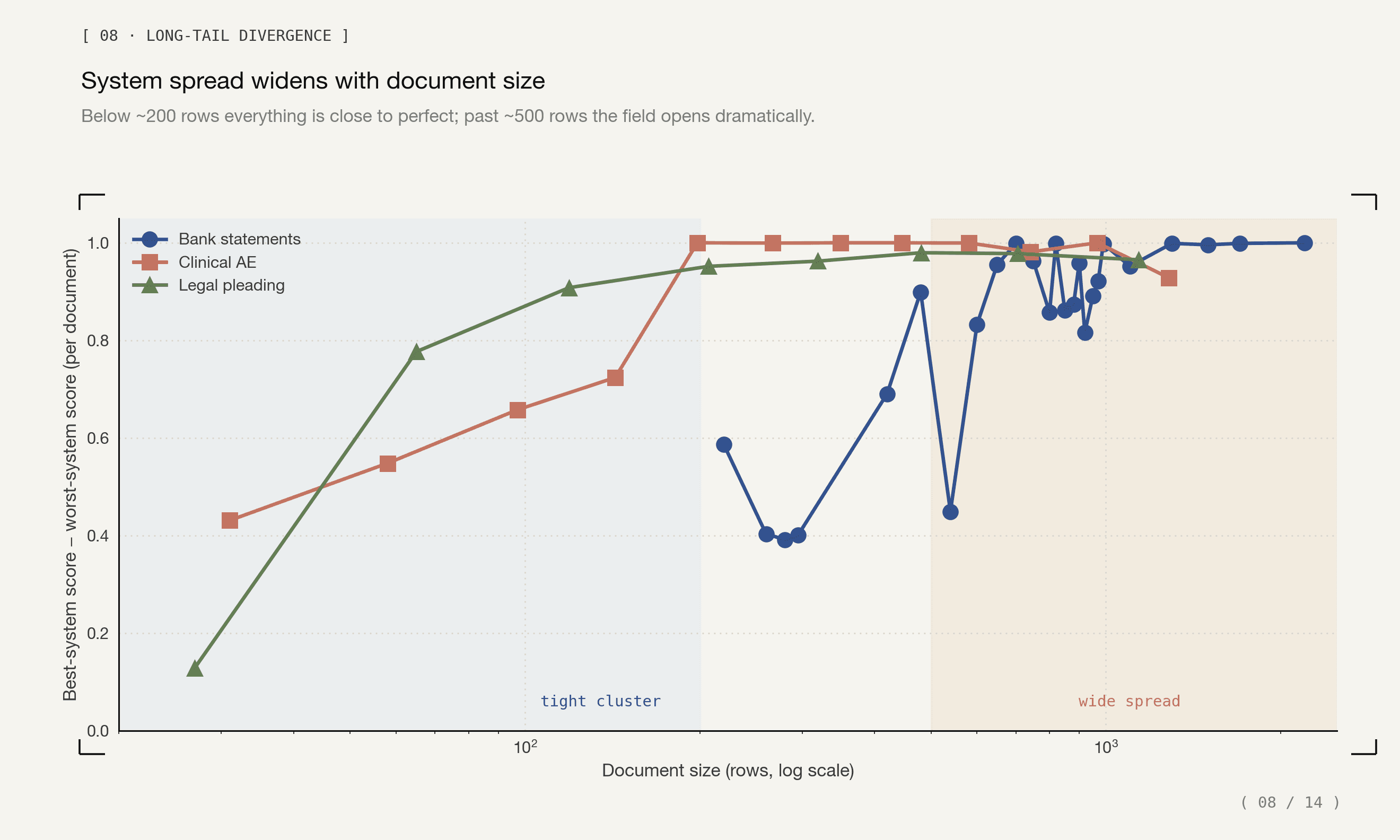
1. The gap opens in the long tail
Below roughly 200 rows, many systems look close to production-ready. Past that point, the benchmark separates systems that keep enumerating from systems that collapse into partial arrays, sparse samples, or terminal failures.
System spread widens with document size
2. Completion changes how accuracy should be read
Completion rate illustrates why reliability has to sit next to accuracy. Some systems scored well on documents they completed. But across the full benchmark, incomplete or failed runs changed the ranking once every document was counted.
For production pipelines, "accurate when it returns" is a different property from "reliably returns the whole output." The benchmark reports both so teams can see whether a system is failing loudly, failing silently, or completing with degraded quality.
Accuracy only matters when the system completes
Extend MAX completed all 45 PDFs with 99.2% aggregate accuracy.
LlamaParse Agentic completed 35 of 45 documents, but returned lower-accuracy outputs, landing at 34.7% aggregate accuracy.
3. Production tradeoffs include speed
Latency matters only after a system can return the right output. LongArray-Extract therefore compares speed against aggregate accuracy instead of treating runtime as a standalone win.
Extend MAX sits on the aggregate Pareto frontier: no evaluated system is both faster and more accurate. The closest peer in accuracy is 2.8x slower while trailing Extend MAX by 1.7 points.
Production tradeoffs include speed
Extend MAX sits on the aggregate Pareto frontier: no evaluated system is both faster and more accurate.
The closest peer in accuracy is 2.8x slower than Extend MAX while trailing by 1.7 points.
4. Raw frontier models need a harness to close the completion gap
Raw frontier models can understand the document and produce accurate rows, especially early in an extraction. Comprehension is not the problem. It is sustained recall and cardinality as the required output grows.
As arrays get longer, raw model outputs become incomplete: tail rows are omitted, records are sampled from the middle of the document, or valid JSON is returned before every expected item has been captured.
Extend MAX closes that gap by wrapping the frontier model into part of a dedicated extraction harness. The system controls extraction, manages context across smaller units of work, reconciles row boundaries across the full document, and verifies the merged array before downstream systems receive it. The model focuses on understanding the document; Extend MAX handles the orchestration required to return complete arrays at scale.
90 records across 12 pages
Speed, completion, and error rate are derived from aggregate benchmark latency, completion, and accuracy. Fast lanes can still finish with fewer correct rows.
5. Production pipelines need more than long context
LongArray-Extract shows that this problem is not solved by context length alone. The document can fit in the model window and still fail because the required answer is too large to emit reliably in one turn.
For production document workflows, that difference shows up as missing transactions, adverse events, facts, or citations that downstream agents treat as complete records. The stronger approach is orchestration around the model: choose document representations, route by expected output load, split work deliberately, preserve global context, repair boundary issues, and verify the merged array before downstream systems receive it.
How Extend MAX extraction works
Long array extraction requires Extend MAX.
Extend MAX extraction uses dynamic chunking for large documents based on table size, table density, and schema complexity. The chunks are chosen to preserve semantic context as much as possible, so related rows, headers, sections, and field definitions stay connected during extraction.
The extraction then makes multiple passes through the full document. Those passes persist split context across the long-document extraction, reconcile rows that cross chunk boundaries, and verify that the merged array is complete before the output is returned.
Smaller models run alongside the main extraction to detect and fix mechanical issues around page boundaries, section transitions, repeated headers, continuation rows, and other boundary conditions that can create dropped, duplicated, or merged records.
